rand()%n is
wrong
For a first post, we’ll start with an idea that’s come up twice for me in the last few weeks.
Lately, I’ve been exploring writing more software in C & C++, in
an attempt to start solving problems in new domains. During that effort,
I’ve been reading Accelerated C++1. In
that book, I came across a brief discussion2 of
the issues that arise when trying to map the uniform random numbers
generated by rand().
What’s wrong with
rand()%n?
If somebody had asked me to generate a uniform random number from \(1\)–\(N\), I would have said sure, no problem:
#include <stdlib.h>
int naive_rand(int n) {
return (rand() % n) + 1;
}And this will definitely generate a pseudo-random number, assuming
you seed rand(). But that number won’t be
uniform.
Consider rand()’s summary:
From theReturns a pseudo-random integer value between
0 andRAND_MAX(0andRAND_MAXincluded).
rand()
docs
Ok, so let’s see. Assume RAND_MAX is 16, and we want a
random number between 1 & 7. Let’s see how values of
RAND_MAX map to output values.
rand() output |
naive_rand() output |
|---|---|
| 0 | 1 |
| 1 | 2 |
| 2 | 3 |
| 3 | 4 |
| 4 | 5 |
| 5 | 6 |
| 6 | 7 |
| 7 | 1 |
| 8 | 2 |
| 9 | 3 |
| 10 | 4 |
| 11 | 5 |
| 12 | 6 |
| 13 | 7 |
| 14 | 1 |
| 15 | 2 |
| 16 | 3 |
This generation method results in 1, 2, and 3 having a better chance of being generated than the other numbers! In fact, the chance of getting a 1–3 is about 50% more likely than getting a 4–7.
The problem here is in the mapping. The numbers 0–16 are generated uniformly, but they don’t uniformly map to 0–6, using the modulo operator.
At the time, I didn’t realize that this phenomenon has a name – modulo bias.
A simple approach to fix modulo bias: rejection sampling
To account for this bias, we can think of our output values \(1-N\) as “buckets” to choose from, and select one of the buckets by distributing all the values from \([0,{\tt RAND\_MAX}]\) evenly into our \(N\) buckets.
Once we have fewer than \(N\) elements left to distribute (so the buckets would have uneven numbers), we simply throw the rest of the values away.

With this strategy, output values that fall outside the range that can be evenly distributed have an equal number of potential inputs that will cause them to be selected.
The following implementation satisfies this strategy:
int uniform_rand(int n)
{
// n is the "number of buckets" we want to use
const int bucket_size = RAND_MAX / n;
int result;
do {
result = rand() / bucket_size;
} while (result >= n);
return result + 1;
}That gives us the following result:
rand() output |
unfiorm_rand() output |
|---|---|
| 0 | 1 |
| 1 | 2 |
| 2 | 3 |
| 3 | 4 |
| 4 | 5 |
| 5 | 6 |
| 6 | 7 |
| 7 | 1 |
| 8 | 2 |
| 9 | 3 |
| 10 | 4 |
| 11 | 5 |
| 12 | 6 |
| 13 | 7 |
| 14 | NO MAPPING – Try again |
| 15 | NO MAPPING – Try again |
| 16 | NO MAPPING – Try again |
How slow is this?
At first glance, this seems obviously slow. If nothing else, there’s a loop in there now. The question then, is: “How many times does the loop execute?”
To understand how many times we’d expect the loop to run, we need to
know the probability that a given rand() call will give us
a number outside of the appropriate range (a “discarded” number). That
probability is: \[
{\# discarded\ values} \over {\tt RAND\_MAX}
\]
To count this set, we first need to identify it. Can we determine the worst-case scenario of “discarded” values?
We’ll do this in two steps:
- Given some bucket count, \(N\), how many elements are discarded in the worst case?
- How does that value compare to
RAND_MAX?
Finding the worst-case number of discarded elements
Let’s try examples.
First, assume \(N =
2\). When we have two buckets, we’ll distribute the
elements from 0 – RAND_MAX into each bucket
alternatingly. If there are an even number of elements in the range,
we’ll distribute all of them. (Nothing thrown away). If
there’s an odd number, we’ll have to keep 1 element not
distributed. So, for N=2, we throw away, at most,
1 value, no matter what RAND_MAX is.
Next, let’s try \(N =
3\). In this case, we do the same thing, adding one
element to each bucket, until we are out of elements. Now, if
RAND_MAX was a multiple of 3, then each bucket would get
the same number. Otherwise it’s either one or two away from a multiple
of 3, so either one or two elements are left over. Thus, the worst case
for \(N=3\) is 2.
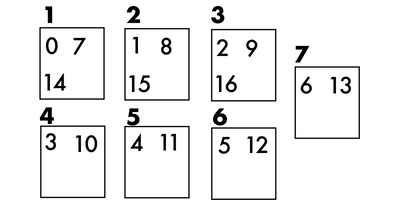
… And so it goes. Here’s the worst-case for \(N=7\):

Continuing on, we find a pattern: the “worst-case” scenario is throwing away \(N-1\) values.
Comparing discarded
elements to RAND_MAX
We’ve found that \(N-1\) is the
worst-case number of elements we will discard. Let’s see what value of
RAND_MAX will mean that those invalid \(N-1\) elements are chosen as frequently as
possible.
Now, obviously we have to distribute at least one element into every bucket, because otherwise there would be values in \([1, N]\) we could not choose!
The “key insight” here is that, to get the worst-case scenario, we shouldn’t distribute more than one value per bucket, since distributing more values than that just makes it more likely that we’ll select a “good” value!
And thus we’ve found our worst-case scenario:
After distributing \(N\) elements (one
per bucket) from RAND_MAX, there are \(N-1\) elements remaining.
Or, algebraically: \[ \eqalign{ \ & {\tt RAND\_MAX} - N &= N - 1 \cr & \implies 2N &= {\tt RAND\_MAX} + 1 \cr & \implies N &= \left\lfloor{{\tt RAND\_MAX} \over 2}\right\rfloor \cr } \]
So, the worst case number of thrown-away values occurs when \[ N \approx {{\tt RAND\_MAX}\over2} \]
Plugging that back into our original expression for probability of “looping again”: \[ {{\# discarded\ values} \over {\tt RAND\_MAX}} \approx {{{\tt RAND\_MAX} / 2} \over {\tt RAND\_MAX}} = {{1 \over 2}} \]
So the probability of generating a usable number is \(\approx{1\over 2}\), And thus, we expect to run the loop about twice per call. Not too shabby; that’s still constant time!
Practical application
In general, this isn’t often all that practically useful, considering most languages give you a function with a uniform distribution from \(0-1\), which maps very easily to \(N\). But modulo bias as a concept is generally useful.
Further Research
There are more sophisticated techniques for working around modulo bias, so at some point I’d love to learn more of them! If you already know some and you’d like to explain them to me, please feel free to drop me a line.